
네이버 부동산 기사 제목을 크롤링하고자 합니다. 네이버 부동산 > 뉴스 > 우리동네뉴스로 접속하면 지역의 시군구별 기사를 볼 수 있습니다. 다음 페이지로 넘어가거나 다른 지역을 선택하면 링크가 함께 바뀌기 때문에 동적 크롤링에 사용되는 Selenium이 아닌 BeautifulSoup을 사용합니다. 먼저 접속 시 기본으로 보여지는 첫 페이지에서 기사 제목을 크롤링합니다.
from bs4 import BeautifulSoup
import pandas as pd
import requests
link = 'https://land.naver.com/news/region.naver?city_no=1100000000&dvsn_no=1114000000&page=1'
url = requests.get(link)
html = BeautifulSoup(url.text)
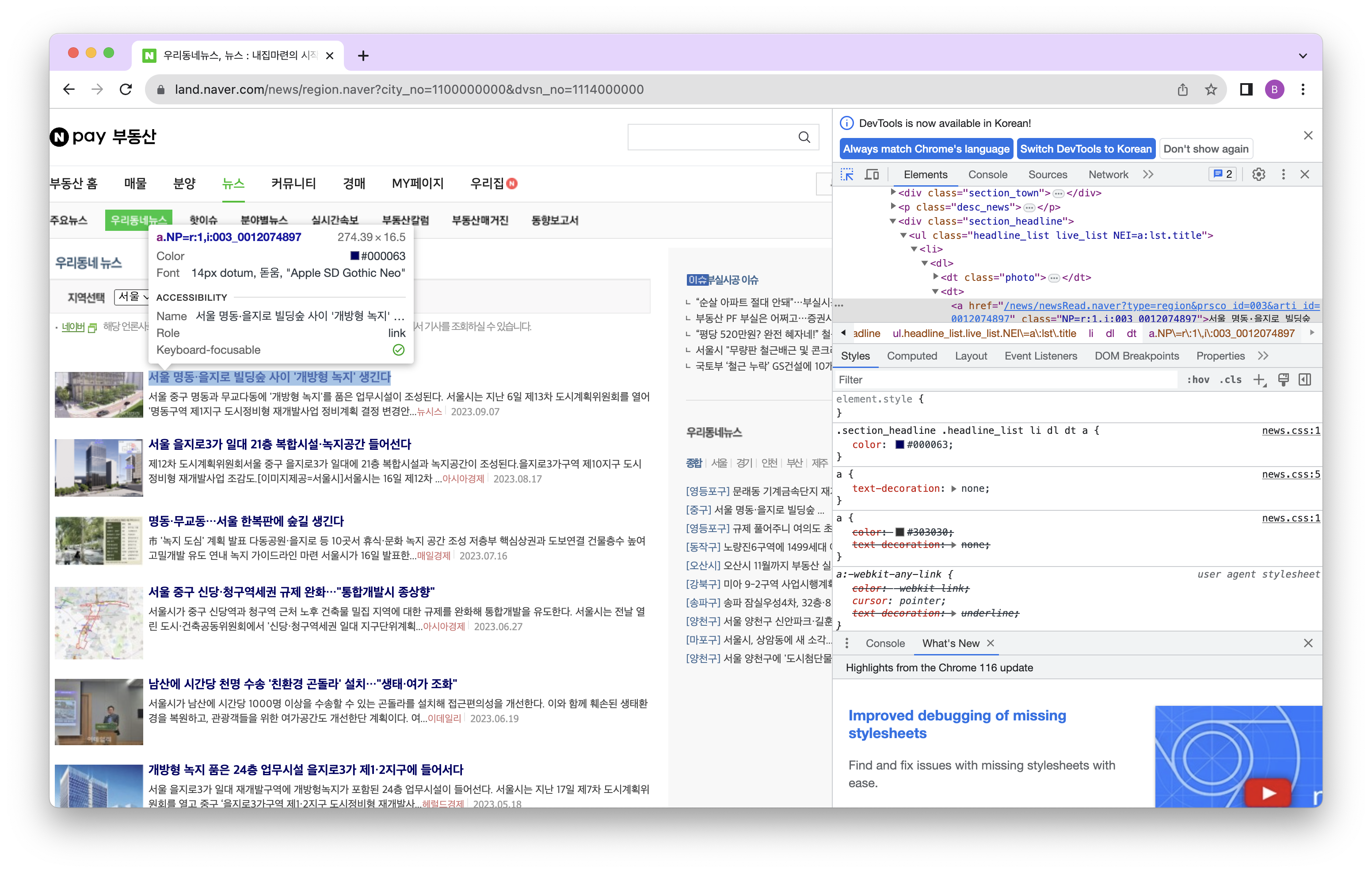
정확히 뉴스 기사 제목만 가져오기 위해 점차 작은 범위로 한정해갑니다.
news = html.find('div', attrs = {'class':'section_headline'})
dl_tag = news.find_all('dl')
title = [dl_tags.find('dt', class_ = 'photo').find_next('dt').find('a').text for dl_tags in dl_tag]다만, 사진이 있는 기사와 사진이 없는 기사가 있기 때문에 try, except 문을 사용하여 각 경우에 다르게 가져옵니다.
title_lst = []
date_lst = []
for n in tqdm(range(1,10)):
link = f'https://land.naver.com/news/region.naver?city_no=1100000000&dvsn_no=1114000000&page={n}'
url = requests.get(link)
html = BeautifulSoup(url.text)
news = html.find('div', attrs = {'class':'section_headline'})
dl_tag = news.find_all('dl')
for dl_tags in dl_tag:
try:
title = dl_tags.find('dt', class_ = 'photo').find_next('dt').find('a').text
except:
title = dl_tags.find('dt').text
title_lst.append(title)
date = dl_tags.find('span', class_ = 'date').text
date_lst.append(date)
if pd.to_datetime(date) <= datetime(2021,1,1):
break
'Data Science' 카테고리의 다른 글
| Mac M1 Konlpy (0) | 2023.09.16 |
|---|---|
| Mac M1 Chromedriver (0) | 2023.09.16 |
| pyLDAvis A task has failed to un-serialize 오류 (0) | 2023.09.09 |
| Google Colab에서 Konlpy 설치 (0) | 2023.09.09 |
| 토픽 모델링 (0) | 2023.09.09 |